Designing a Real-Time Voice AI Platform
In this post, I walk through a AI voice agent design based on the architecture below. The voice communication system supports:
- real-time
- stateful
- highly concurrent
- sensitive to even small delays
This is definitely not meant to be a perfect design. These are basically my notes on how I would reason through it right now.
What I Want the System to Do
- users can start and end a voice session
- clients can continuously stream audio to the platform
- system processes audio and generates a response
- system streams audio response back to the client
What Matters Most
- low latency (< 1 second e2e)
- high concurrency (handle millions of calls simultaneously)
- high availability
- horizontal scalability
- observability (latency, throughput, error rates)
Latency feels especially important here because even small delays can break the illusion of a real-time conversation.
If the system answers correctly but too slowly, the UX will still be bad.
Initial Thought (and why it breaks)
My first instinct was:
just open a connection, stream audio, process it, and return a response
That works conceptually, but breaks down quickly when you consider:
- audio arrives continuously (not in batches)
- many users are connected at the same time
- processing takes a lot of time (STT, LLM, TTS)
- failures can happen mid-call
- latency accumulates across multiple stages
This is not just a processing problem.
It is a coordination problem under real-time constraints.
High-Level Architecture
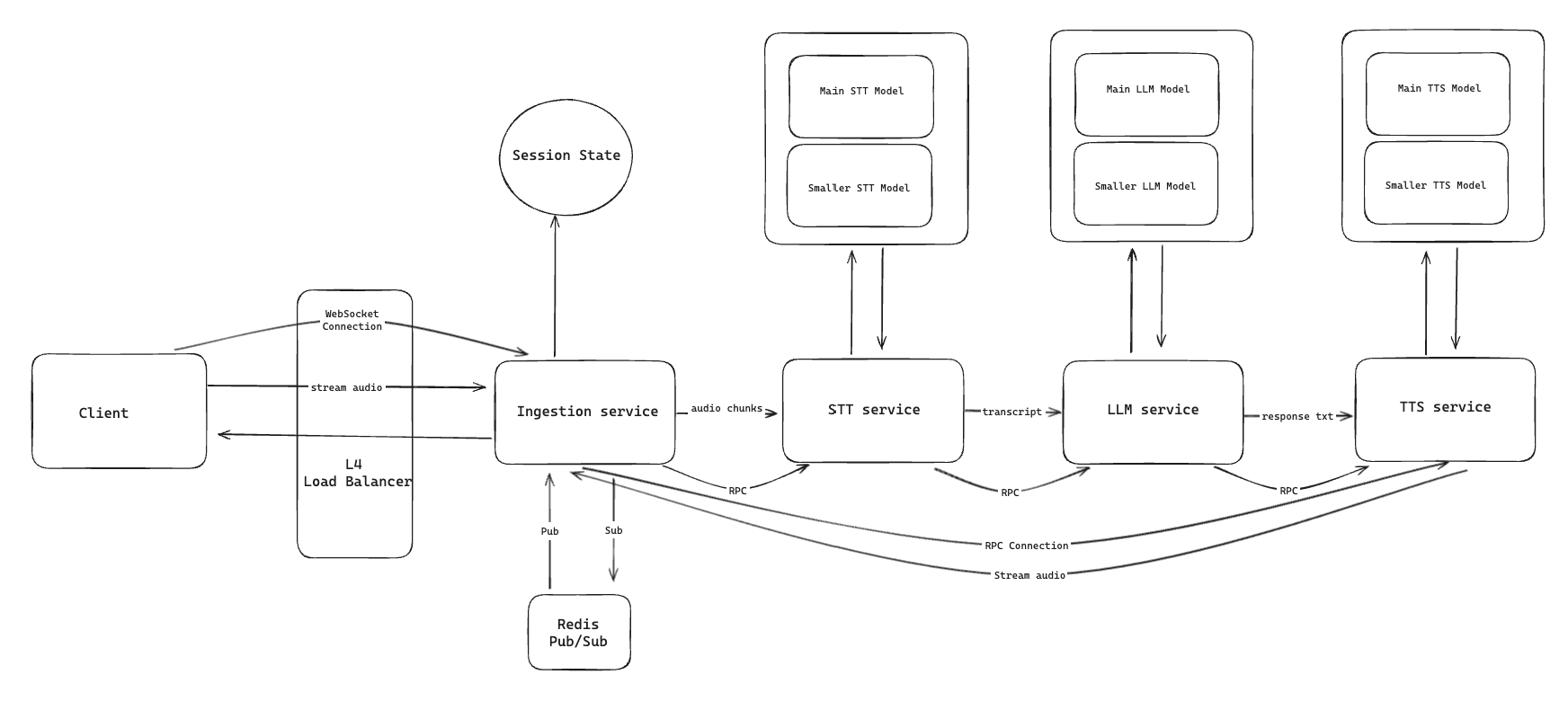
The basic loop still looks simple:
- client opens a session
- client streams audio
- system processes audio
- system streams response back
To make that work at scale, I would break the system into a few layers:
Edge Layer (load balancing, routing) Ingestion / Session Gateway Processing Pipeline
- speech-to-text (STT)
- orchestration / LLM
- text-to-speech (TTS) Response Streaming Layer Async Systems (logging, billing, analytics)
The ingestion layer is the part I keep coming back to because it acts like the bridge between the client connection and the rest of the platform.
Data Flow
A typical call would look like:
- client creates a session
- client opens a persistent WebSocket connection
- client streams audio chunks continuously
- ingestion layer receives and routes audio by session
- STT converts audio into text
- LLM generates a response
- TTS converts response text into audio
- audio is streamed back to the client
- usage and logging events are emitted asynchronously
- session ends and resources are cleaned up
Deep Dives
Latency
This is the first thing I would worry about.
Latency comes from a bunch of places:
- network hops
- buffering
- model inference
- response generation
To keep latency low:
- use persistent streaming connections instead of request/response
- avoid unnecessary buffering
- minimize hops in the hot path
- stream partial responses when possible
One thing that stood out to me here is that queues are useful in a lot of backend systems, but I would be careful about putting them directly in the real-time path.
They help with decoupling, but they can also quietly add delay.
Scaling
Each call should be treated as an independent session.
That gives me a cleaner mental model:
- horizontal scaling across ingestion nodes
- distribution of sessions across regions
- independent scaling of processing layers
For global scale:
- deploy across multiple regions
- route users to the nearest healthy region
Backpressure
If processing falls behind:
- data starts piling up
- latency increases
- responses become useless
To handle this:
- use bounded buffers
- monitor lag between stages
- throttle intake if necessary
- shed load when overloaded
- autoscale the bottleneck layer
This part feels really important because delayed responses are almost as bad as failed responses in a voice system.
The goal is to stop small slowdowns from turning into a pileup the whole system cannot recover from.
Failure Handling
If a node fails mid-call:
- client should reconnect to a healthy node
- system resumes from recent recoverable state if possible
Tradeoff:
- seamless failover is complex
- fast reconnect is simpler and often sufficient
I would probably prioritize fast recovery over perfect handoff.
Perfect continuity sounds nice, but it adds a lot of complexity very quickly.
Protocol Choices
Both WebSockets and gRPC support streaming.
- WebSockets are better for client connections (especially browsers as they natively support it)
- gRPC is better for internal service-to-service communication
A common pattern:
- WebSockets at the edge
- gRPC internally
State Management
Not all state needs to be preserved.
My first instinct is to keep only the minimum session state I really need:
- session ID
- recent transcript
- current processing stage
Tradeoff:
- more state = better recovery
- more state = more complexity
Bottlenecks
The most likely bottlenecks are:
- number of active connections per ingestion node
- network bandwidth
- inference capacity (CPU/GPU)
- queue buildup between stages
- shared metadata stores
My guess is that the processing / inference layer becomes the main bottleneck most of the time, especially once the system gets enough traffic.
Tradeoffs
WebSockets vs gRPC
ease of use vs performance
Streaming vs queues
low latency vs decoupling
Stateless vs stateful
scalability vs session continuity
Fast reconnect vs seamless failover
simplicity vs user experience
Multi-region vs complexity
lower latency vs operational overhead
Kubernetes Mapping
- ingestion layer → Deployment + HPA (scale on # of connections)
- processing services → Deployment + HPA
- inference → GPU-backed node pools
- Services handle internal routing
- autoscaling based on custom metrics (not just CPU)
Connection heavy services are often I/O-bound, so CPU alone is not a reliable signal.
Final Thoughts
This system initially looked like a streaming problem.
But the deeper I went, the more it became about:
- controlling latency
- coordinating distributed state
- handling backpressure
- scaling under real-time constraints
That is my first design dealing with an AI agent. Lots of improvements to be made here. Stay tuned.