Designing a Job Scheduler system
In this post, I walk through a distributed job scheduler design based on the architecture below. The system supports:
- Creating and scheduling jobs
- Retrieving job status and execution history
- Reliable asynchronous execution
- Long-term scheduling for jobs scheduled days in advance
- Horizontal scaling to support high parallelism
- Retry handling with DLQ support
This is definitely not meant to be a perfect design. These are basically my notes on how I would reason through it right now.
The Shape of the System
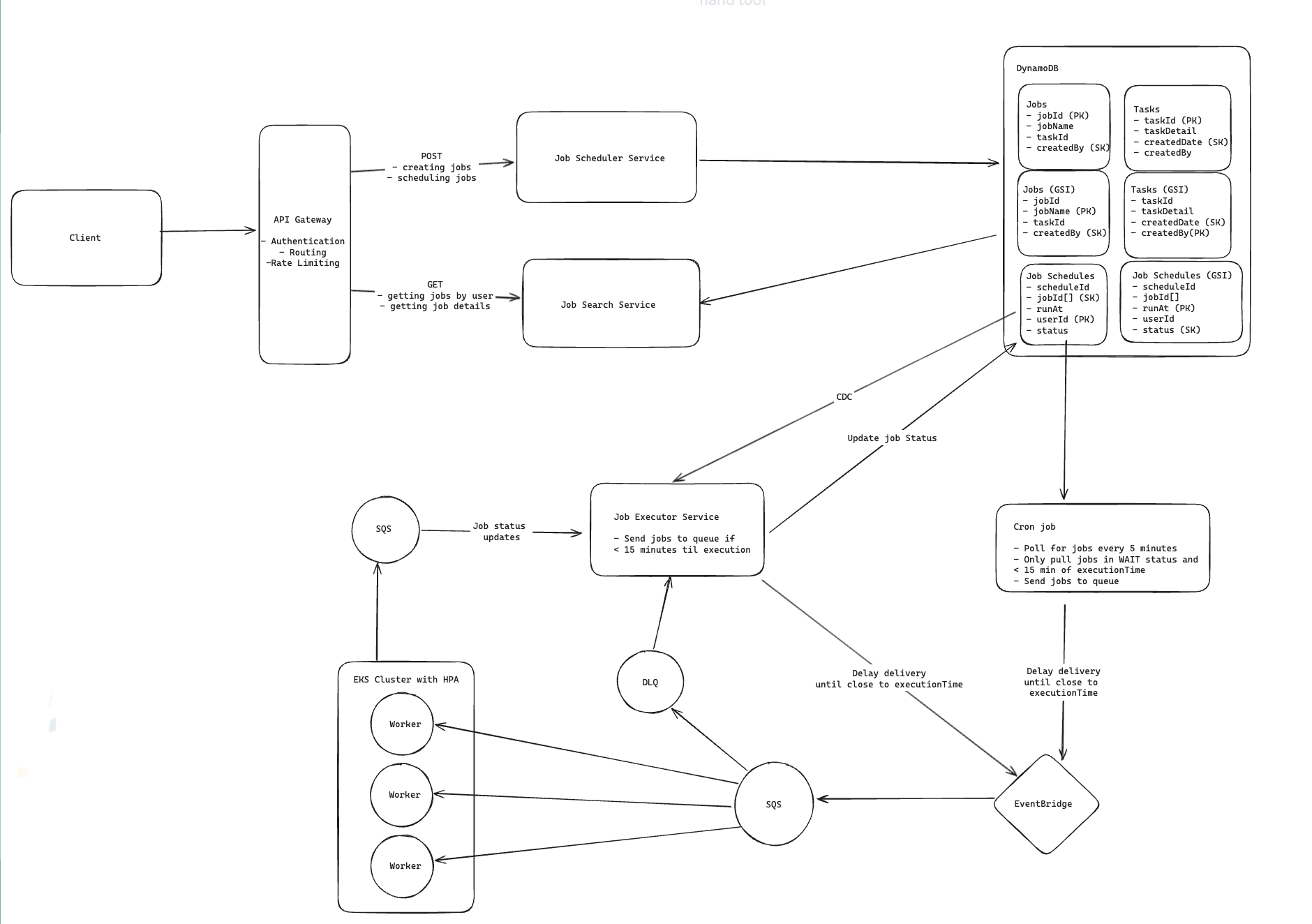
The rough architecture in my head looks like this:
- API Gateway handles auth, routing, and rate limiting
- Job Scheduler Service accepts create/schedule requests
- Job Search Service handles reads for status/history
- DynamoDB stores jobs, tasks, and schedule records
- Job Executor Service decides when a job should move toward execution and processes status updates
- Cron Job periodically checks long-term scheduled work
- EventBridge holds jobs until they are close to execution
- SQS buffers executable work and status events
- Worker Fleet on EKS runs jobs in parallel
- DLQ catches jobs that repeatedly fail
The main idea I like here is:
- DynamoDB is where future work lives durably
- EventBridge helps with short-term timing
- SQS + workers handle scalable execution
That feels cleaner to me than trying to make one component do everything.
Where My Head Went First
My first instinct was:
user schedules a job -> put it in a queue with a delay -> worker runs it later
That works only up to a point.
The problem is that delayed queues usually have limits, and they are not a great place to keep jobs that need to wait for days.
So if a user schedules something three days out, I do not really want to pretend the execution queue is also my long-term storage layer.
That was the point where the design split into two phases for me:
- store future schedules durably
- promote them into the execution path when they are actually close enough to run
That split solved a lot of the design questions.
Data I’d Store
I’d keep three main entities in DynamoDB:
Jobs
This is the logical job definition.
Example fields:
jobIdjobNametaskIdcreatedBy
Tasks
This stores task-specific metadata.
Example fields:
taskIdtaskDetailcreatedDatecreatedBy
Job Schedules
This is the one I care about most for scheduling.
Example fields:
scheduleIdjobId[]runAtuserIdstatus
The Job Schedules table is basically the source of truth for “what should run in the future and what state is it in now?”
Write Path
When a user creates or schedules a job, this is the flow I’m imagining:
- client sends a
POSTrequest through the API Gateway - API Gateway authenticates, rate limits, and routes to the Job Scheduler Service
- Job Scheduler Service writes the schedule record into DynamoDB
- A CDC-style event flow notifies the Job Executor Service that a new schedule has been created
- Job Executor Service checks how close the job is to its execution time
At that point I’d split jobs into two buckets:
- near-term jobs these can move into the timing/execution path right away
- far-future jobs these stay in DynamoDB until they get closer
That feels like the core design choice in this system.
How It Actually Runs
Once a job is close enough to execute, I’d push it through something like this:
- Job Executor Service or the Cron layer forwards it toward EventBridge
- EventBridge waits until it is very close to the target execution time
- EventBridge sends the executable message into SQS
- workers on EKS poll SQS and run the job
- workers send status updates to a separate status queue
- Job Executor Service consumes those updates and writes the latest state back to DynamoDB
I like the separate status queue because it keeps workers simpler.
Instead of every worker directly updating the main schedule record, they can just emit events like:
RUNNINGSUCCESSFAILED
and the Job Executor Service becomes the single place that updates job state.
Read Path
Reads are much simpler in my head than writes.
If a user wants to check scheduled jobs or execution history:
- client sends a
GETrequest through API Gateway - request goes to Job Search Service
- service uses the authenticated user identity
- service queries the
Job Schedulestable byuserId - current status gets returned
Possible statuses might be:
WAITINGQUEUEDRUNNINGSUCCESSFAILED
I generally like separating the read path from the execution path here because it makes the user-facing query path easier to reason about.
The Part I’d Worry About Most: Timing Accuracy
If the requirement is “execute within 2 seconds of the scheduled time,” I would not wait until the exact timestamp to start doing work.
That sounds obvious, but I think it matters a lot.
The better approach is:
- move the job toward execution a little early
- let EventBridge hold it until very close to run time
- have workers already polling and ready
- keep some worker capacity pre-warmed
Otherwise the system ends up trying to do routing, provisioning, and execution setup right at the deadline, which is exactly when you do not want extra latency.
So to me, the scheduler is not just deciding what runs.
It is also deciding when to start preparing for the run.
What About Jobs Scheduled Days Ahead?
This is where I think the Cron layer earns its keep.
When a schedule is first created, I do not want to immediately force it into the execution queue if it is days away.
Instead:
- keep it durably in DynamoDB
- run a periodic Cron job
- have that Cron job look for schedules that are now close enough
- forward those into EventBridge
- let EventBridge handle the final short-term timing
So the model becomes:
- long-term holding area = DynamoDB
- short-term timing layer = EventBridge
- actual execution buffer = SQS
That layering made the design click for me.
It avoids abusing SQS as a multi-day scheduler while still keeping the actual execution path queue-based.
Scaling to 10,000 Concurrent Jobs
If I want to support a lot of jobs running in parallel, the part I trust most is the queue + worker model.
The rough scaling story is:
- executable jobs land in SQS
- many workers poll concurrently
- workers run on EKS
- HPA scales the worker fleet based on load
Why I like that:
- queues absorb bursts
- execution is decoupled from submission
- workers can scale horizontally
- retries are easier to handle
I also would not want workers to do too much coordination logic.
My preference is:
- workers execute
- workers emit status
- Job Executor Service owns schedule state transitions
That keeps the worker side focused on running jobs instead of trying to be mini schedulers.
Pre-Warming Workers
One thing I mentioned in my notes was pre-warming workers to avoid cold starts.
If I had to pick a simple way to do that, I’d probably look ahead into upcoming scheduled demand.
Something like:
- query jobs due in the next 30 minutes
- estimate how much worker capacity that implies
- compare that to currently available capacity
- raise the worker floor before the spike hits
It does not need to be perfect to be useful.
Even a rough demand forecast is better than waiting until the queue is already full and then reacting late.
Later on I’d make that smarter with:
- average job duration
- tasks per job
- concurrency per worker
- historical spikes
But the first version can stay pretty simple.
Failure Handling
There are really two different failure cases here.
1. The worker runs the job and it fails visibly
Examples:
- downstream dependency fails
- code throws an exception
- job returns an explicit failure
In that case I’d want:
- retries with exponential backoff
- retry count tracking
- DLQ after max attempts
Once it lands in the DLQ, the Job Executor Service can mark the schedule as FAILED.
2. The worker disappears mid-execution
This one is trickier because the failure is not always explicit.
That is where SQS visibility timeout helps.
The rough idea:
- worker picks up message
- message becomes temporarily invisible
- if worker finishes, it acknowledges the message
- if worker dies, visibility timeout expires
- another worker can pick the message back up
That gives the system a reasonable way to recover from silent worker failures without inventing some custom lease system from scratch.
If Something Hits the DLQ
If a job ends up in the DLQ and the user later fixes the underlying issue, I would not replay the raw DLQ message directly.
I’d rather let the user create a new execution attempt through the normal scheduling flow.
So the re-trigger path in my head is:
- user sees the failed job in the read API
- user submits a new scheduling request
- system creates a new schedule record
- that new record goes through the normal scheduling and execution pipeline
I like that better because it is cleaner operationally and better for auditability.
You get a fresh execution attempt with its own lifecycle instead of mutating a dead one in a weird way.
Tradeoffs
What I like about this design:
- durable storage for future schedules
- cleaner separation between scheduling, timing, and execution
- handles both near-term and far-future jobs
- scales well with queue-based workers
- retries and DLQ handling fit naturally
- status tracking is user-visible
What makes it more expensive conceptually:
- there are a lot more moving parts
- Cron promotion adds operational overhead
- status propagation adds another async hop
- the system is easy to understand at a high level, but harder to operate well
That said, this kind of complexity feels justified to me once the requirements include both precise timing and large-scale parallel execution.
What I’d Take Away From This
The biggest thing this design made me realize is that a scheduler is really doing three different jobs:
- remembering what should run in the future
- timing when it should get pushed closer to execution
- executing actually running the work reliably at scale
Once I separated those three in my head, the system became much easier to reason about.
That is probably the main lesson I’d keep from this one.