Designing a Scalable Web Crawler
This is my attempt at thinking through a web crawler design.
I like this one because I’ve created this on my own before, but then once I started thinking about having to be able to handle at a large scale and with all these robots.txt restriction added since the beginning of my career as a software engineer, things got a lot harder:
- URL scheduling
- deduplication
- retry handling
- politeness
- freshness
This is definitely not meant to be a perfect design. These are basically my notes on how I would reason through it right now.
Initial Thought (and why it stops being simple)
My first instinct was:
just start with some seed URLs, fetch pages, extract links, and keep going
That is the basic loop, but it breaks down pretty quickly once you think about crawling the real web.
The things that immediately make it harder are:
- the same page can show up under multiple URLs
- some pages fail temporarily
- some domains should not be hit too aggressively
- a page being crawled once does not mean we are done forever
That was the shift for me:
This is not just a “fetch pages” problem.
It is really a scheduling and coordination problem.
High-Level Architecture
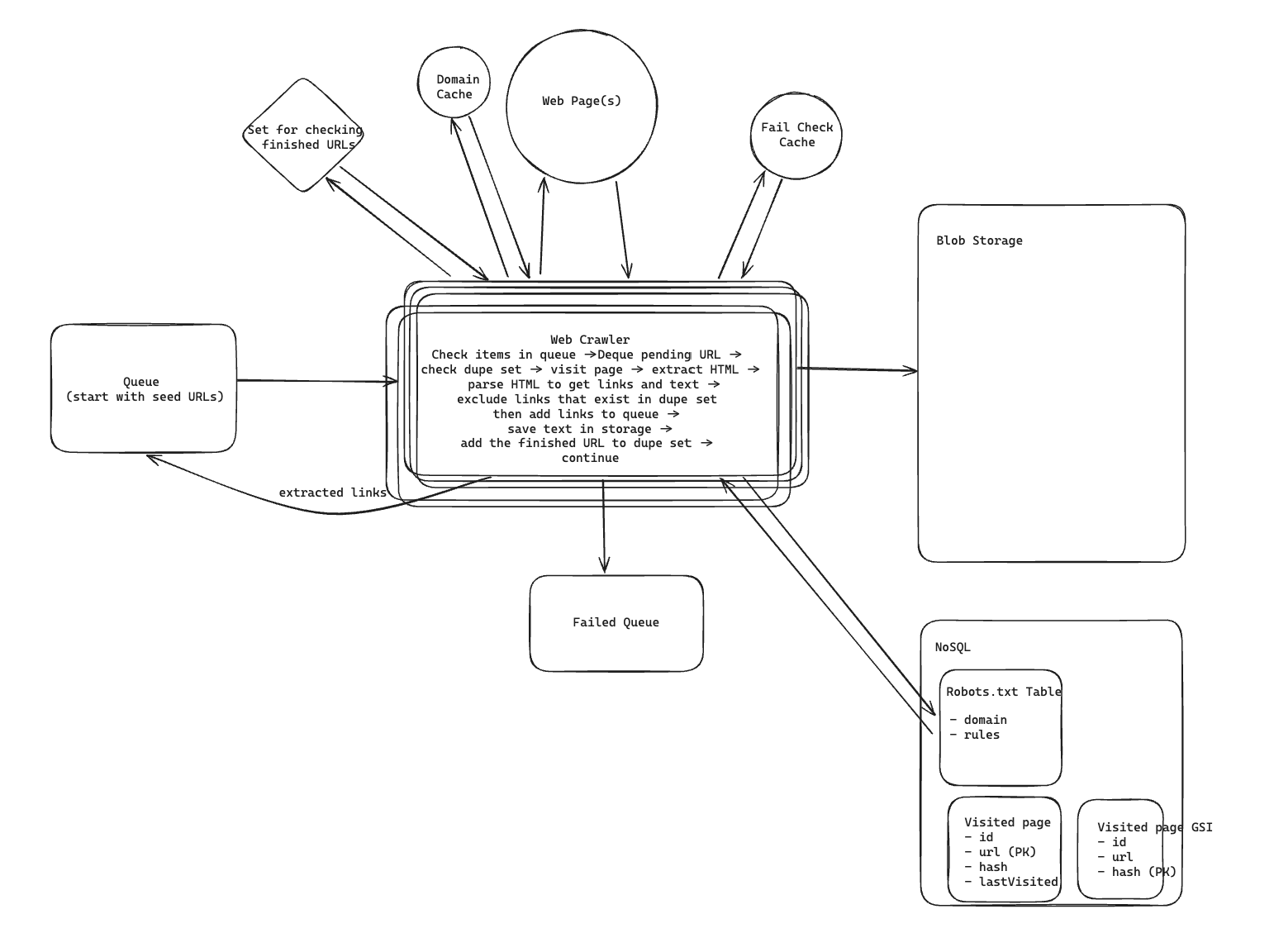
The main loop in my head is still pretty simple:
- start with seed URLs
- push them into a crawl queue
- workers pull URLs from the queue
- workers fetch pages
- parse links and content
- store useful data
- enqueue newly discovered links
But to make that work at scale, I would split the system into a few responsibilities:
- Crawl Queue for pending URLs
- Crawler Workers for fetching and parsing pages
- Visited URL Store to avoid crawling the exact same URL over and over
- Content Fingerprint Store to detect duplicate content across different URLs
- Domain Metadata Store to track rate limits and last access times per domain
- Robots Rules Store to cache
robots.txt - Failure Queue for URLs that keep failing
- Content Storage for raw HTML or extracted text
What makes this system interesting to me is that none of these parts are individually that exotic.
The hard part is how they interact under scale.
The Basic Crawl Flow
If I ignore scale for a second, the happy path looks like this:
- worker dequeues a URL
- normalize it
- check whether we have already visited it recently
- check whether crawling it is allowed
- fetch the page
- parse out text and links
- store the content
- enqueue newly discovered links
- mark the URL as visited
That is the core loop I keep coming back to.
Everything else in the design is basically there to make that loop safe and efficient.
Deduplication
This was one of the first places where the naive version felt incomplete.
At first I thought:
visited set solves duplicates
That only solves exact URL duplication.
But in practice the same content can show up under:
- tracking parameters
- printer-friendly pages
- mobile vs desktop URLs
- mirrored routes
So I think about deduplication in two layers.
URL-level deduplication
Before fetching, I would normalize URLs:
- lowercase host where appropriate
- remove obvious tracking params
- standardize path formatting
Then I would check a visited store.
That helps avoid re-crawling the same URL shape over and over.
Content-level deduplication
Even after URL normalization, different URLs can still return the same page.
So after fetch, I would generate a content fingerprint and check whether we have already seen it.
If the content hash already exists, I may still record that the URL was seen, but I would avoid storing or processing the full content again.
That separation helped clarify the design for me:
- URL dedupe avoids repeated fetches of the same address
- content dedupe avoids repeated storage of the same page
Retry Handling
I do not want transient failures to make us lose pages completely.
But I also do not want a bad URL to get retried forever.
So the retry flow I like is:
- fetch fails
- increment retry count
- re-enqueue with delay
- if retries exceed threshold, move URL to failure queue
That delay matters.
Without it, a bunch of failing URLs can create tight retry loops and waste crawler capacity.
For state, I would keep something simple like:
url -> retryCount
in a fast key-value store.
This is one of those small details that feels boring, but it has a big effect on system stability.
Politeness and robots.txt
This part feels non-negotiable to me.
A crawler that ignores robots.txt or hammers the same domain too fast is just badly behaved.
So for each domain, I would want to cache:
- parsed
robots.txtrules - last access time
- crawl delay
- temporary backoff state if the domain is failing
The flow in my head is:
- first time we see a domain, fetch
/robots.txt - parse and cache the rules
- before each request, check whether the path is allowed
- also check whether enough time has passed since the last request to that domain
If not enough time has passed, I would re-enqueue the URL with a delay instead of crawling it immediately.
The important thing here is that politeness is not some side feature.
It directly affects scheduling.
Multiple Workers and the Shared State Problem
Once I start thinking about scale, this is where it gets more interesting.
We do not crawl billions of pages with one worker.
We need many workers pulling from a shared queue in parallel.
That gives us throughput, but it also creates coordination problems.
Now all workers need shared access to things like:
- visited URLs
- content fingerprints
- domain access metadata
- cached
robots.txt
The domain coordination piece especially matters.
If two workers grab two URLs from the same domain at nearly the same time, they can accidentally violate the domain rate limit unless we coordinate.
So before a worker fetches a URL, I would want something close to an atomic check/update on domain metadata:
- read domain state
- verify delay requirement is satisfied
- atomically update
lastAccessedAt - proceed with fetch
That atomic part is what keeps politeness rules from breaking under concurrency.
Scaling to a Very Large Crawl
If the goal is something like crawling 10 billion pages in under 5 days, the main answer is horizontal scale.
We add more workers and let them pull from the same crawl queue.
That part is conceptually straightforward.
The harder question is what becomes the bottleneck.
The bottlenecks I would worry about most are:
- duplicate checking
- queue throughput
- domain-level coordination
- metadata reads/writes
- content storage throughput
So even though the workers are doing the fetching, the real scaling pressure often lands on the shared metadata layer.
That is why I would expect a distributed key-value store or cache to be doing a lot of heavy lifting here.
Freshness
One thing I did not appreciate at first is that “visited” does not really mean “done forever.”
For many crawlers, pages need to be revisited.
Otherwise the data gets stale.
So instead of treating the visited store as a permanent do-not-touch list, I would store something like:
urlhashlastVisited
Then when a page shows up again:
- if it is still considered fresh, skip it
- if it is stale, allow it to be crawled again
That changes the meaning of the visited table pretty significantly.
It is no longer just dedupe state.
It also becomes part of recrawl scheduling.
For stored content, the simple version I would start with is just overwriting the old copy and updating the timestamp.
If version history matters, then I would keep multiple snapshots, but I would not start there unless the product really needs it.
Data Model
The rough tables / stores I picture are:
RobotsTxt
domainrules
VisitedPage
urlhashlastVisited
VisitedPageByHash
hashurl
DomainMetadata
domainlastAccessedAtcrawlDelaybackoffUntil
RetryCount
urlretryCount
This is not fancy, but I like it because it maps pretty directly to the problems the crawler has to solve.
What This Design Taught Me
The main things this design made click for me were:
- a crawler is really a scheduler as much as it is a fetcher
- URL duplication and content duplication are different problems
- politeness rules are central to the architecture, not an afterthought
- retries need delay and failure isolation or they get messy fast
- freshness changes how you think about visited state
Final Thoughts
A web crawler sounds simple when you first describe it:
start with some URLs, fetch pages, extract links, repeat.
But once I add retries, deduplication, politeness, freshness, and distributed workers, it starts feeling much more like a coordination problem than a simple scraping loop.
That is what makes this one fun to think about.