Designing a Ticketmaster-like System
This is my attempt at thinking through a Ticketmaster-like system.
I like this one because it forces you to think about two very different problems at the same time:
- event search
- real-time seat selection
- correctness under insane traffic spikes
What makes this system interesting to me is that most of the hard part is not really CRUD. It is mostly about contention, temporary state, and making sure two people do not think they bought the same seat.
This is not meant to be a perfect design. These are basically my notes on how I would reason through it right now.
Initial Thought (and where it gets tricky)
My first instinct was:
just store events and tickets in a database, then update a seat row when someone books
That sounds fine until you picture a high-demand concert.
Now thousands or millions of people may be refreshing the same event page, clicking the same few seats, and trying to check out at nearly the same time.
That was the shift for me:
This is not just an event catalog problem. It is a concurrency-control problem.
Once I started looking at it that way, the design felt more like:
- search and browsing on one side
- seat reservation and booking correctness on the other
High-Level Architecture
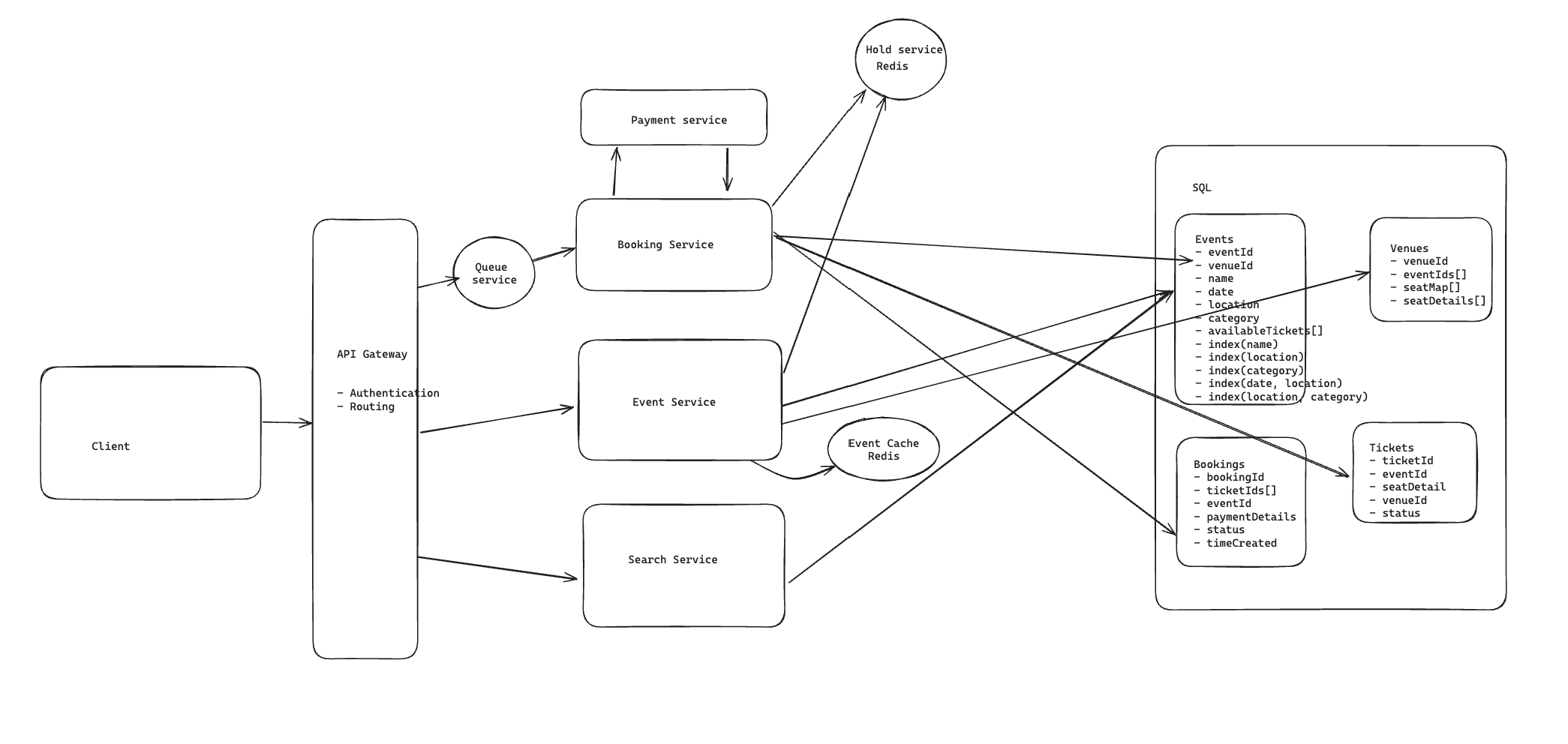
The biggest thing shaping my design is that reads and writes want very different things here.
For browsing and search, I want:
- low latency
- lots of horizontal scale
- caching wherever it helps
For booking, I care much more about:
- correctness
- preventing double booking
- handling temporary holds safely
So in my head I split the system into a few responsibilities:
- Event Service for event metadata and details
- Search Service for discovery queries
- Booking Service for seat holds and checkout
- Redis for short-lived reservation state
- SQL DB as the source of truth for events, tickets, and bookings
Viewing Event Details
The easy path is just viewing a specific event.
That flow in my head is:
- client sends
GET /events/{eventId} - request goes through API Gateway
- gateway routes to Event Service
- Event Service reads from the Events database
- event details come back to the client
This part is pretty standard. The main thing I would care about is caching hot events because popular pages are going to get hammered.
Searching for Events
At first I thought maybe search could just live in the same service as event reads.
I do not really like that after thinking about it more.
Search has different access patterns:
- text search
- filtering by category, city, date
- ranking and relevance
So I would separate it into a Search Service.
For a simpler version, you could query indexed fields in a relational database. But once queries start looking more like:
- “Drake concert in LA”
- “NBA games this weekend”
it starts feeling more like a search engine problem than a plain database lookup.
That is why I would keep Search Service logically separate from Event Service. It gives you better scalability and lets you optimize search independently.
Booking Seats
This is where the design gets interesting.
The user flow is roughly:
- user opens event page
- client loads event details, seat map, and currently available tickets
- user selects seats
- client sends booking request
The important thing is that “seat available when page loaded” does not mean “seat still available when checkout starts.”
So the Booking Service cannot trust the client. It has to re-check availability at the moment of reservation.
If the seat is already taken or on hold, reject it.
If it is still available, move it into a temporary reserved state first rather than marking it permanently sold immediately.
That temporary state is the key idea for this whole system.
Two-Phase Booking
The part I kept coming back to was: how do we stop users from losing seats mid-checkout without permanently locking inventory?
The model that makes the most sense to me is two-phase booking.
Phase 1: Hold the seat
When a user selects a seat and starts checkout:
- store the hold in Redis
- attach a TTL like 10 minutes
- mark that seat as temporarily unavailable
I like Redis here because this is short-lived state. It is fast, and expiration is built into the model.
Phase 2: Confirm the booking
If payment succeeds:
- remove the hold
- mark the ticket as
SOLD - create the booking record in the database
If payment never completes:
- TTL expires
- hold disappears
- seat becomes available again
That feels like the right tradeoff to me because we preserve correctness without forcing abandoned carts to lock seats forever.
Read Path for Availability
One subtle thing here is that available seats are not just whatever the database says is unsold.
You also have to account for seats currently on hold.
So when the client asks for available seats, the system should roughly:
- read unsold tickets from the database
- subtract seats currently held in Redis
- return the filtered result
That way the UI reflects both permanent sales and temporary reservations.
Failure Handling
One obvious failure mode is:
what if the hold service crashes and seats get stuck?
That is why I would want Redis set up with replication and failover, not as a single fragile node.
But even more importantly, the TTL is doing a lot of safety work here.
Even if something goes wrong, the hold should not live forever.
That is one of the reasons I like expiration-based temporary state for this kind of problem.
Scaling Reads
The read side could get huge for a major event.
If millions of users are browsing event pages and seat maps, I would want to scale that path aggressively:
- load balancer in front of services
- horizontally scaled Event Service instances
- in-memory caching for hot events
- potentially sharded event/ticket data if the dataset gets large enough
This is one of those systems where the read traffic and write traffic behave very differently.
Reads want scale and caching.
Writes want careful coordination.
Sharding Tradeoffs
If I had to shard event data, my first thought would be to shard by eventId.
That gives you a pretty natural distribution for reads and writes tied to one specific event.
The downside is that it is not great for cross-event queries like:
- events in San Francisco
- comedy shows this weekend
- concerts by category
That is another reason I would not rely on the main relational database alone for discovery queries.
Sharding by eventId helps operationally, but it does not solve search.
Search Improvements
If the product needs richer discovery, I would introduce Elasticsearch.
That helps with:
- full-text search
- filtering by category, location, date
- ranking by relevance
The mental split I have is:
- SQL DB for correctness and transactional data
- Elasticsearch for fast discovery
That is very similar to how I think about the Yelp design too. The main database should not be forced to do every job.
Real-Time Seat Updates
Another thing that matters here is making the seat map feel live.
If one user grabs a seat, other users should see that change quickly.
The two obvious options are:
- WebSockets
- Server-Sent Events (SSE)
My default choice would probably be SSE if the main requirement is just one-way seat updates from server to client.
That feels simpler than full WebSockets while still giving users a real-time view of what is disappearing.
The flow would be something like:
- Booking Service changes seat state
- server emits update event
- connected clients refresh those seats in the UI
Virtual Waiting Room
This is the other big idea that feels necessary for really hot events.
Without a waiting room, the booking system can get overwhelmed instantly, and even if the backend survives, the user experience becomes chaos.
So I would add a queue in front of the booking flow for high-demand events.
In my head the flow is:
- users enter queue with
eventIdandsessionId - queue orders them fairly
- only a limited number of users are allowed into active booking at once
- when users finish or abandon the flow, the next users are admitted
You could implement that with Redis, Kafka, SQS, or something similar depending on how much control you want.
The important part is not the exact tool. It is the admission control.
That is what protects the booking path from turning into a thundering herd problem.
Tradeoffs
The tradeoffs I keep landing on are:
- Redis holds add extra system complexity
- search becomes eventually consistent if Elasticsearch is introduced
- real-time updates and waiting rooms add operational overhead
But the upside is worth it:
- better user experience during spikes
- much lower chance of double booking
- cleaner separation between browsing scale and booking correctness
What I Learned
The biggest things this design reinforced for me were:
- the hardest part is not storing tickets, it is coordinating access to them
- temporary state matters a lot in booking systems
- high-scale reads and correctness-sensitive writes usually want different architectures
- fairness mechanisms like waiting rooms are part of system design, not just product polish
Final Thoughts
What I like about this problem is that it forces you to care about state transitions.
A seat is not just available or sold.
It may be:
- available
- on hold
- sold
- released after timeout
That is what makes the design interesting to me.
Once I started viewing it as a system for managing contested state under load, the architecture made a lot more sense.