Designing a Yelp-like System
This is my attempt at thinking through a Yelp-like system.
I liked this one because it mixes a few different things at once:
- search (text + geo)
- relational data (users, reviews)
- ranking + performance
This definitely is not meant to be a perfect design. These are basically my notes on how I’d reason through it right now.
🧠 Initial Thought (and why it breaks)
My first instinct was:
“Just query a database with filters like name, category, and location”
But that falls apart quickly for queries like:
- “ramen near me”
- “best sushi in SF”
That’s when it clicked:
👉 This is not just a database problem — it’s a search system problem
🏗️ High-Level Architecture
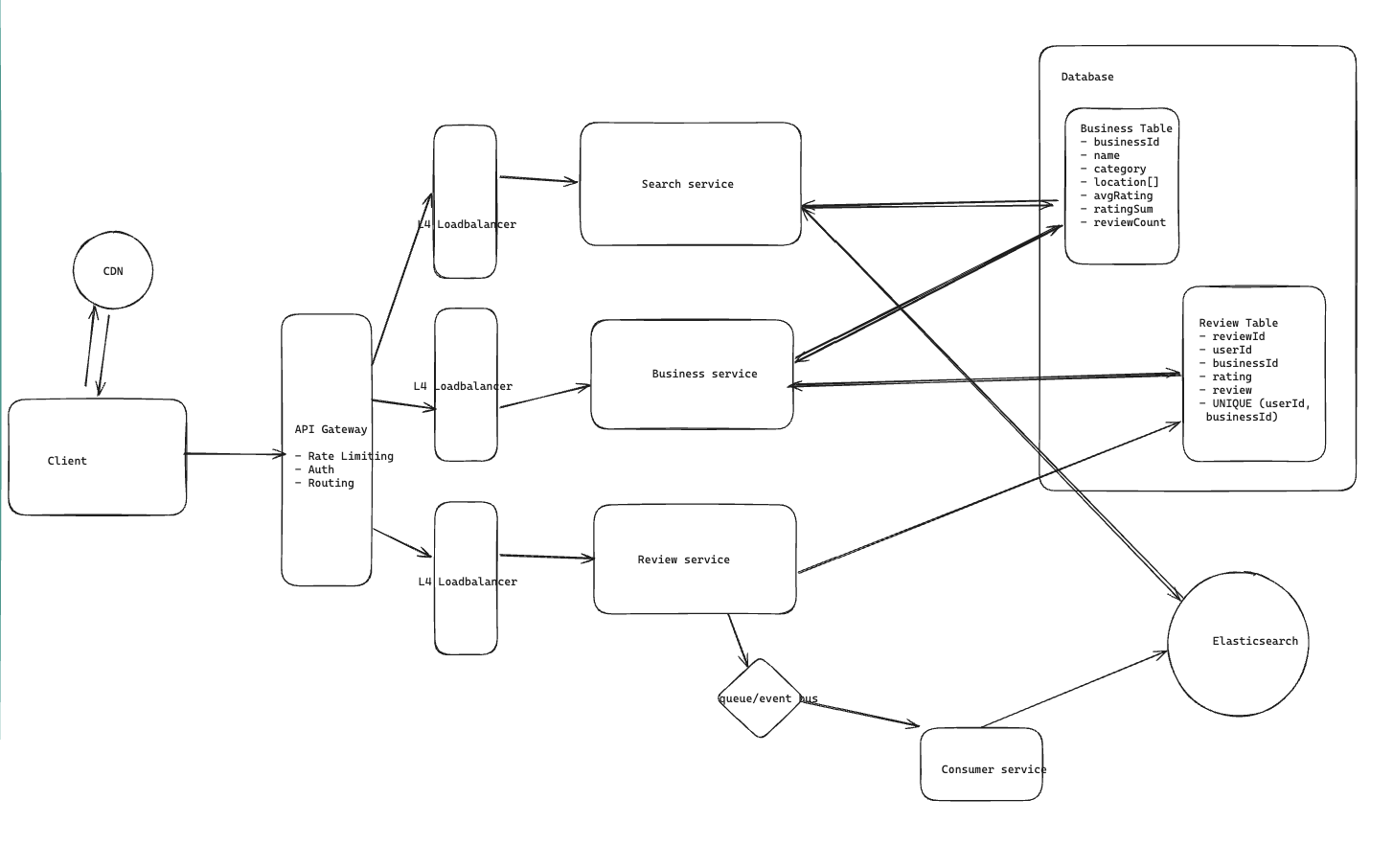
The biggest thing that shaped my design was realizing that search and writes have very different needs.
So in my head I split the system into two paths:
- search (read-heavy, low latency)
- writes (business + reviews)
For search, I want low latency and flexible querying, so I’d send those requests to Elasticsearch.
For writes, I still want the SQL database to be the source of truth. So business updates and review writes go to SQL first, then I update Elasticsearch asynchronously after that.
The event bus and indexer are basically just there so I can keep Elasticsearch in sync without blocking the user-facing write path.
- SQL DB → source of truth (correct data)
- Elasticsearch → fast search (text + geo + ranking)
🔍 Search Flow
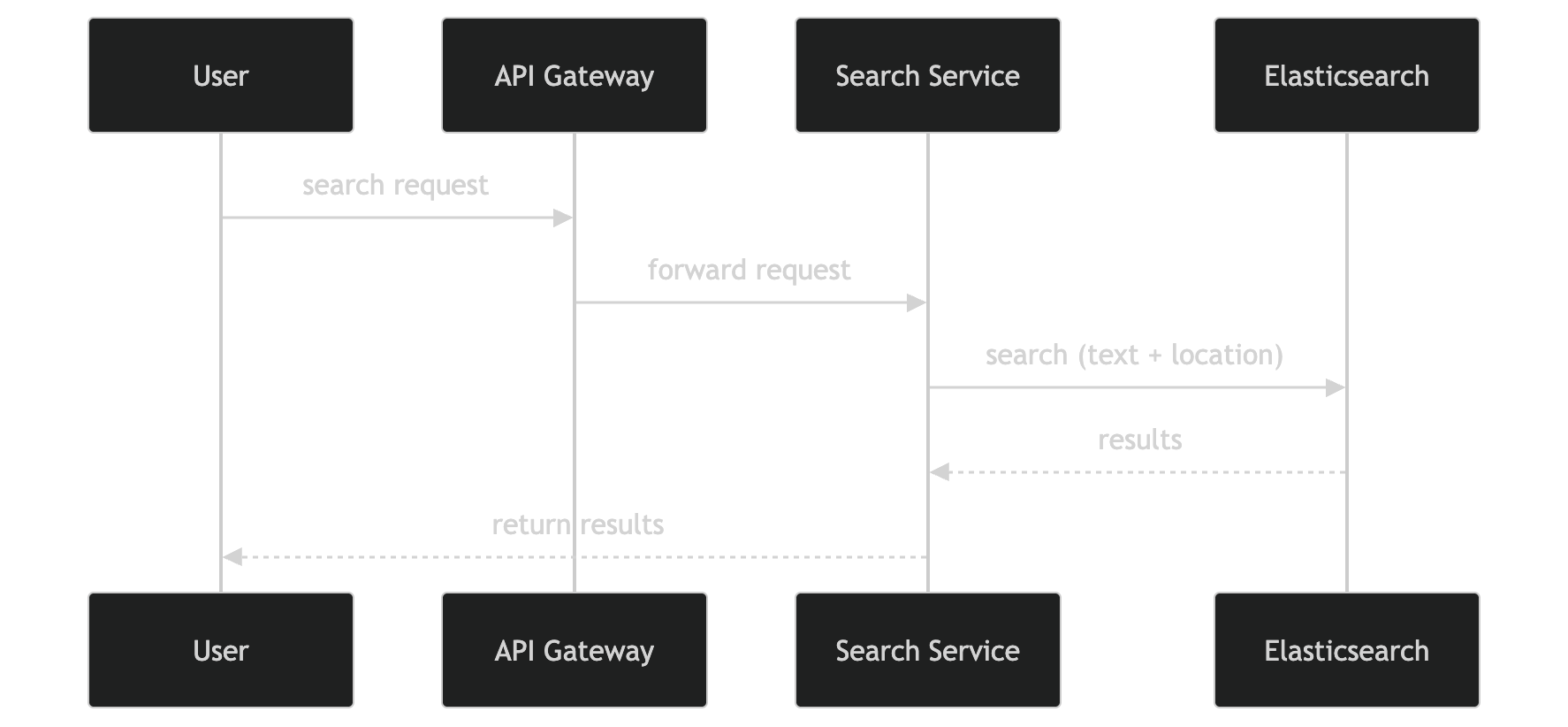
When I first thought about this, I assumed I’d just query the database.
But for something like:
- “ramen near me”
- “best sushi in SF”
that gets messy fast.
That is the point where this stopped feeling like a normal CRUD-style database problem to me.
So instead, I’d have the request go through a Search Service and then straight to Elasticsearch.
Elasticsearch handles:
- text matching (ramen, sushi, etc.)
- filtering (category)
- geo queries (distance)
- ranking
and returns the best results.
That just feels like a much more natural fit than trying to force the main database to handle all of that efficiently.
📍 Geo Search (Key Insight)
At first I thought we’d store something like “within 5 miles” in the DB.
That doesn’t really make sense though.
Instead:
- each business stores lat/lon
- distance is applied at query time
{
"location": {
"lat": 37.77,
"lon": -122.41
}
}
Then Elasticsearch does:
- “find everything within X miles”
That was one of the small mindset shifts for me. You don’t store the radius result ahead of time. You store coordinates and let the search engine evaluate distance when the query comes in.
⭐ Reviews + Ratings
The naive thought here was:
calculate average rating from all reviews each time
That’s too slow.
What makes more sense to me is precomputing the aggregates.
Store:
ratingSumreviewCountavgRating
Update on write:
ratingSum += rating
reviewCount += 1
avgRating = ratingSum / reviewCount
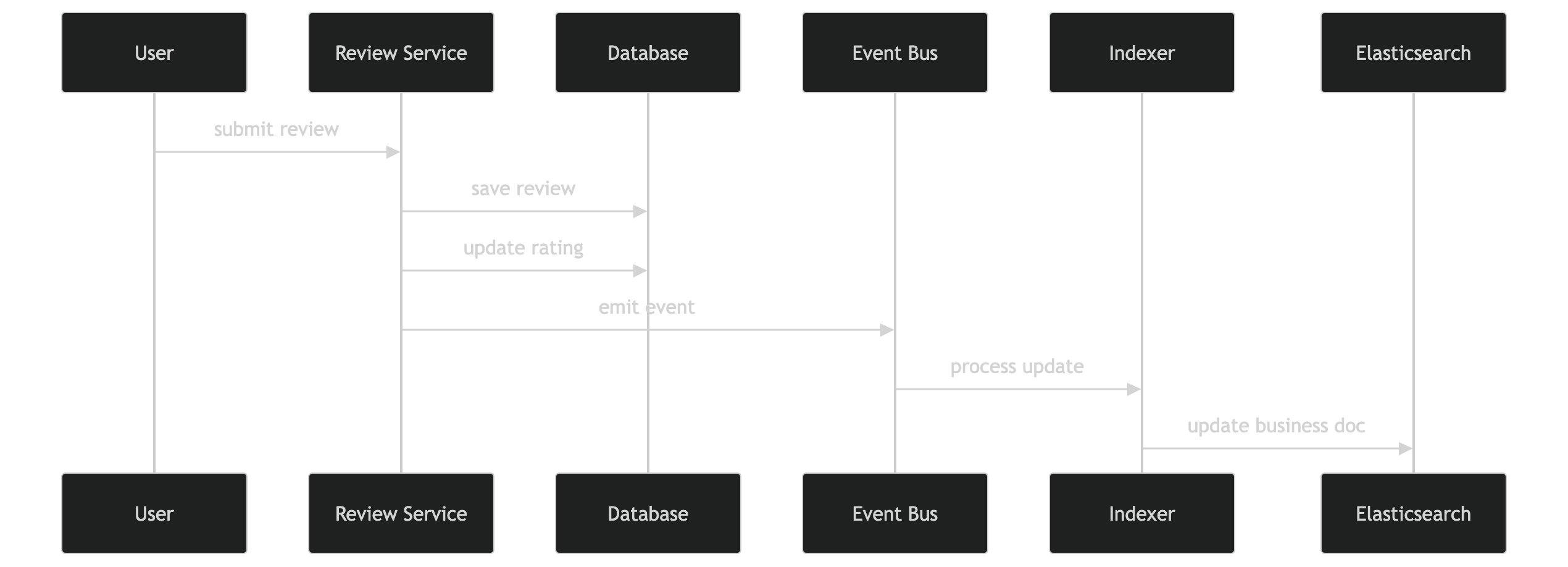
This part took me a bit to understand.
The important thing is: 👉 don’t block the user while updating search
So when a user submits a review:
- I write it to the database
- update the business rating (sum + count)
- then emit an event
That event eventually updates Elasticsearch.
So search results stay close to real-time, but I’m not slowing down the write path.
✍️ One Review Per User
One constraint I’d want is:
- one user → one review per business
Solution
UNIQUE(user_id, business_id)
Optional:
- use upsert to allow edits instead of duplicates
🔁 Keeping Elasticsearch in Sync
This was one of the parts I went back and forth on the most.
There are a couple ways I could think about it:
- application-level events
- CDC / change data capture off the database
The direction I lean toward first is application-level events because it feels easier for me to reason about while I’m still practicing this stuff.
So the mental model I’m using is:
- write to DB first
- publish an event
- consumer/indexer updates Elasticsearch
That gives me a write path that stays fast, while still keeping search reasonably fresh.
📍 Searching by Location Name
Users don’t always search by coordinates.
They search:
- “San Francisco”
- “Mission District”
Approach
We store:
- predefined location names
- polygon boundaries
Then the flow in my head is:
- resolve name → polygon
- apply geo filter in ES
Since the list is finite:
- we can cache it heavily
🧩 Mapping Businesses to Locations
When a business is created:
- take lat/lon
- find matching polygons (city, neighborhood)
- store labels on business
The reason I like this is that I’d rather compute that once on write than recompute it on every search query.
🚧 Tradeoffs
- Elasticsearch is eventually consistent
- small delay before updates show in search
- extra complexity (event pipeline)
But:
- much faster search
- better scalability
To me that tradeoff feels worth it for this kind of system.
🧠 What I Learned
The biggest things this made me realize were:
- not all queries belong in the main database
- search systems solve a different kind of problem than SQL databases
- precomputing things like ratings and location labels matters a lot
- event-driven patterns show up really quickly once you care about scale and latency
📌 Final Thoughts
This problem made me realize pretty quickly that designing for search is very different from designing for data storage.
I’m still learning, but this one helped me understand why search-heavy systems need a different mental model than normal CRUD applications.
🚀 Future Improvements
- Redis caching for hot queries
- better ranking:
- distance + rating + popularity
- cursor-based pagination
- sharding for scale