Designing a Rate Limiter System
This is my attempt at thinking through a distributed rate limiter.
At first this problem looked pretty simple, but once I started thinking about scale, shared state, and latency, it got a lot more interesting.
These are basically my notes on how I’d reason through it right now.
🧠 Requirements
Non-Functional
- Availability > Consistency
- Low latency (~<10ms per request)
- Handle ~1M requests/sec across ~10M daily active users
🧱 Core Entities
The main pieces I care about are:
- client identity (
userId, API key, IP, etc.) - request
- rate limit policy
🔌 Interface
The rate limiter really just answers one question:
👉 “Can this request go through or not?”
checkRequest(clientId, ruleInfo) => {
isAllowed: boolean,
remaining: number,
resetTime: timestamp
}
🏗️ High-Level Design
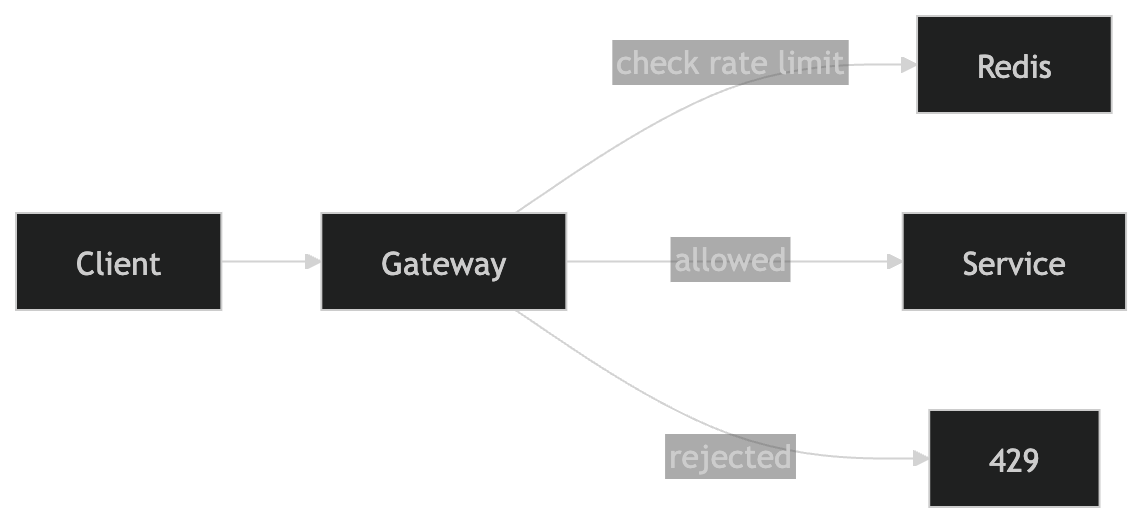
The main thing I care about here is rejecting requests as early as possible.
So instead of putting rate limiting inside each service, I put it at the API Gateway layer.
That way:
- requests get blocked before hitting backend services
- I don’t waste compute on requests I already know I’ll reject
The first real problem I ran into was this:
👉 multiple API Gateway instances need to share the same rate limit state
That’s where Redis comes in.
⚙️ Rate Limiting Algorithm
I initially thought:
just store request count in a hashmap per user
That works at a very basic level, but I don’t really like it for a real system because it feels too rigid and it does not handle bursts very gracefully.
What made more sense to me was Token Bucket.
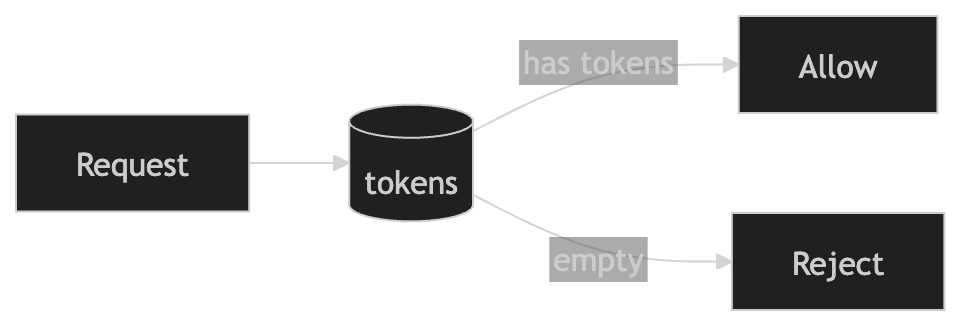
Each user gets:
- a bucket of tokens
- each request consumes 1 token
- tokens refill over time
So the mental model is:
- if there are tokens, allow the request
- if there are no tokens, reject it
I like it because it is simple enough to explain, but still handles bursts better than a rigid counter-based approach.
- allows bursts (good UX)
- smooth rate limiting over time
- easy to reason about
🧠 Where state lives (important)
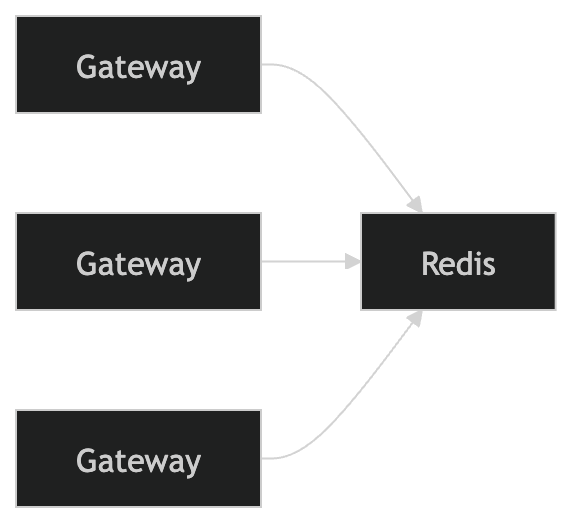
This part matters a lot more than the algorithm itself.
If each gateway kept its own counters, rate limiting would break pretty quickly because the same client could just bounce across instances.
So the state needs to be shared.
That is why I’d keep the rate limit state in Redis and have all gateways read and update the same source of truth.
🚀 Scaling to 1M RPS
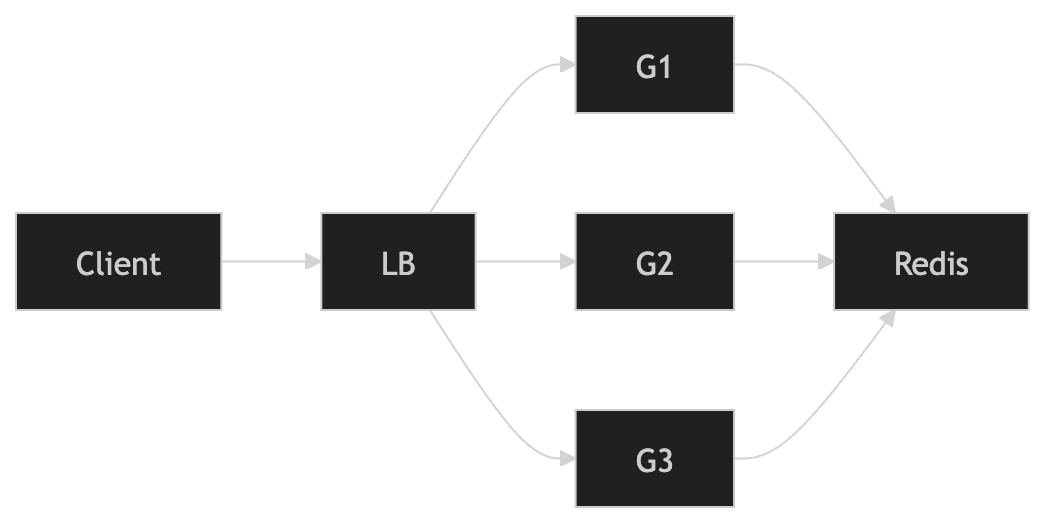
To scale this, I’d keep as much of the system stateless as possible:
- horizontally scale API Gateway
- horizontally scale Redis (Redis Cluster)
- keep everything stateless except Redis
⚡ Keeping Latency Low
This part matters a lot.
If rate limiting gets slow, then every request gets slow.
So the things I’d pay attention to are:
- Keep API Gateway and Redis in same region
- Use persistent connections (no reconnect per request)
- Avoid extra hops (no unnecessary services in between)
The whole point is that this check should be extremely cheap.
🚨 What happens if Redis fails?
This is where tradeoffs come in.
Option 1: Fail Open
- allow all requests
- better availability
- risk: abuse / overload
Option 2: Fail Closed
- block all requests
- safer for critical systems
- worse user experience
My take is that it depends on the kind of system:
- banking / payments → fail closed
- general APIs → probably fail open
Either way, Redis ends up being critical infrastructure here, so I’d still want to reduce the chance of failure as much as possible.
- use Redis Cluster / replicas
- automatic failover
- avoid single point of failure
🧊 Handling Overload / Slow Redis
If Redis becomes slow or unavailable:
👉 API Gateway should start rejecting requests early
Otherwise:
- requests pile up
- system gets overwhelmed
I’d rather degrade early than let the whole system get dragged down.
🔄 Dynamic Rule Updates
Rate limits can change, so there has to be some way to update rules without redeploying everything.
The two options I was thinking through were:
- polling
- push
Polling is simpler. Gateways can periodically ask for the latest rules.
Push is faster, but adds more moving parts.
If I were building this from scratch, I’d probably start with polling because it is easier to reason about, then move to push later if the delay becomes a real problem.
📌 Final Thoughts
This problem made me realize that the hard part is not really the algorithm itself.
- state sharing is the hardest part (not the algorithm)
- Redis becomes critical infrastructure
- small latency here affects every request in the system
👉 rate limiting is one of those things that looks simple until you try to scale it
🚀 Future Improvements
- per-endpoint rate limiting
- adaptive limits based on traffic
- analytics on rate-limited requests
- multi-region support