Designing a URL Shortener System
This is my attempt at thinking through a URL shortener system like Bit.ly.
At first this one felt simple, but once I started thinking about traffic patterns and uniqueness, it got interesting pretty fast.
The parts I kept coming back to were:
- high read traffic
- caching strategies
- uniqueness guarantees
- ID generation
These are basically my notes on how I’d reason through it right now.
🧠 Requirements
Functional
- Shorten a long URL
- Redirect from short URL to original URL
- Optional:
- custom alias
- expiration date
Non-Functional
- Low latency reads (~200ms)
- High availability over strict consistency
- Uniqueness of short URLs
- Scale to:
- ~1B URLs
- ~100M DAU
🧱 Core Entities
The main data I care about is pretty simple:
- short URL
- long URL
- user (optional)
- expiration metadata (optional)
🔌 API Design
Create Short URL
POST /shorten
{
originalUrl,
alias?,
expirationDate?
}
Redirect
GET /{shortURL}
→ 302 Redirect
🏗️ High-Level Architecture
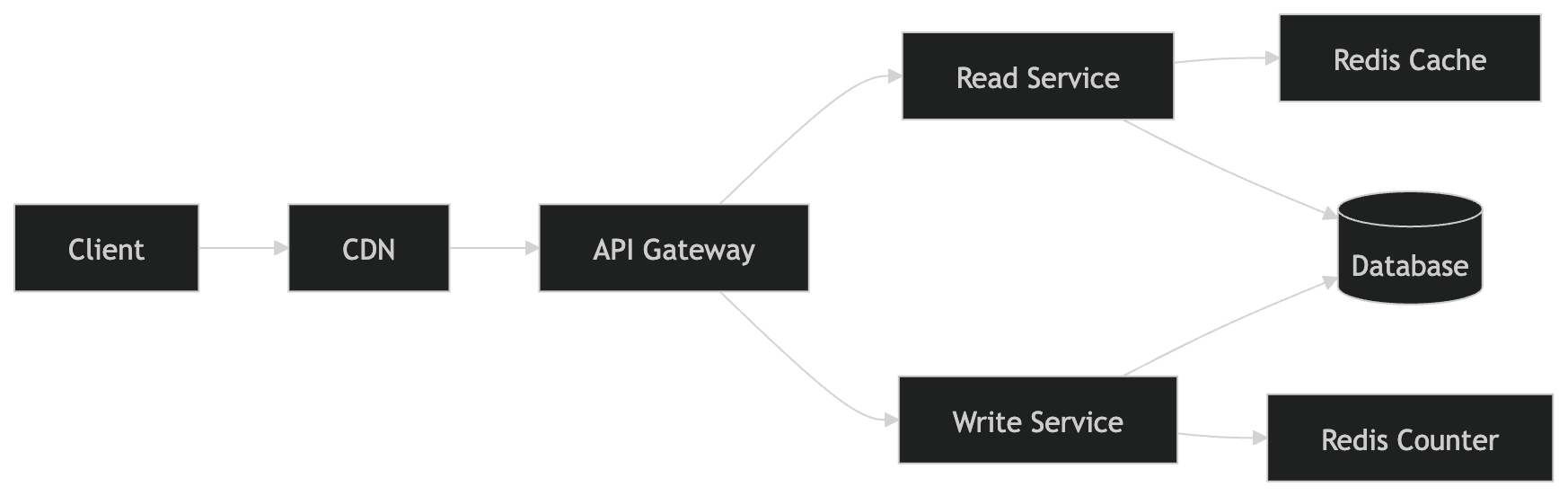
The biggest thing that shaped my design was the fact that this is a very read-heavy system.
Because of that, I’d separate the read path from the write path pretty early instead of treating everything as one service.
For writes, the flow in my head is basically:
- user sends long URL
- request goes through the API Gateway
- Write Service generates a unique ID
- ID gets Base62 encoded
- short URL mapping gets stored in the database
For reads, I want the hot path to avoid the database as much as possible:
- client hits CDN first
- if CDN misses, request goes to the Read Service
- Read Service checks Redis
- if Redis misses, then fall back to the database
- return a
302once the original URL is found
So in my head the database is still the source of truth, but ideally most of the redirect traffic gets absorbed by the cache layers.
🔁 Read Flow (Redirect)
Once I accepted that redirects are the hot path, the read flow felt a lot more straightforward.
When someone visits a short URL, I want the system to find the original URL and send back a 302 as quickly as possible.
The first stop is the CDN. If the redirect is cached there, that is the best case because we avoid the backend entirely.
If it misses, the request goes through the API Gateway to the Read Service. From there, I’d check Redis first for the shortURL -> longURL mapping.
If Redis has it, great, return the redirect immediately.
If Redis misses, then I’d hit the database. If the mapping exists and has not expired, return the long URL and probably warm Redis on the way back. If it is expired or missing, return 404.
So the basic goal is:
- hottest redirects served by CDN
- next layer served by Redis
- database only used on misses
✍️ Write Flow (Shorten URL)
The write path matters less for raw latency, but this is where I care a lot more about correctness and uniqueness.
When a user submits a long URL, I’d send that request through the API Gateway into the Write Service.
The Write Service would:
- generate a unique numeric ID
- encode it with Base62
- save the
shortURL -> longURLmapping in the database
I like this approach more than trying to be clever with hashing because the uniqueness story feels much cleaner.
🔑 How URL Shortening Works
Initially I thought:
“Just hash the URL”
That sounded fine at first, but the more I thought about it, the less I liked it.
Hashing can cause collisions, and once that happens I now need extra logic for detection, retries, and collision handling.
The cleaner option for me was:
- use a global counter
- encode using Base62
Why Base62?
- uses
[a-zA-Z0-9] - short and URL-friendly
Example:
ID: 123456 → "abc123"
⚠️ Uniqueness Problem
We need: 👉 every short URL must be unique
Option 1
- use shortURL as primary key
- retry on collision
This works, but I don’t love it.
Option 2
- use global counter + Base62
- guarantees uniqueness without retries
This is the option I prefer because it reduces ambiguity in the write path.
🧠 Redis Counter Design
I landed on Redis for the counter because it gives me a simple way to generate unique IDs without adding too much complexity.
Main reasons:
- atomic increment (
INCR) - very fast
- easy mental model
counter → increment → unique ID → encode → shortURL
I’m not saying Redis is the only way to do this, but for this level of design discussion it felt like a reasonable place to start.
🚨 What if Redis goes down?
This was one of the first failure cases I got stuck on.
My first thought was that if Redis is responsible for ID generation, it becomes a pretty important dependency.
One approach
- use Redis Cluster
- replication + failover
- multiple nodes
Tradeoff
Replication is async by default, so:
- slight gaps possible
- acceptable tradeoff for availability
For this kind of system, I’m okay with gaps in generated IDs. I care much more about availability and uniqueness than perfectly sequential values.
⚡ Making Redirects Fast
The main idea here is pretty simple:
👉 optimize reads aggressively
1. Primary Key Lookup
shortURL= primary key- O(1) lookup in DB
2. Redis Cache
- cache popular URLs
- avoid DB hits
3. CDN Layer
- edge caching for very hot URLs
🧊 Caching Strategy
- CDN → first layer
- Redis → second layer
- DB → fallback
This is one of those systems where the layering matters a lot more than complicated business logic.
⏳ Handling Expiration
If a short URL has an expiration:
- store expiration in DB
- also apply TTL in Redis
What I’d expect to happen:
- Cache entry expires automatically
- Request goes to DB
- DB sees expired record
- Return 404
📈 Scaling Reads (10k+ RPS)
To handle high read traffic:
- CDN caching
- Redis cache
- horizontally scaled read services
- indexed DB (primary key lookup)
The main idea is just to reduce database traffic as much as possible.
If the CDN can serve the hottest redirects, that is ideal.
If not, Redis should still absorb a lot of the load before anything reaches the database.
After that, I’d horizontally scale the Read Service since it is stateless and the traffic pattern is pretty straightforward.
The database still needs to be indexed on shortURL, ideally as the primary key, so that misses can still be resolved efficiently. But the whole point of the design is that the database should be the fallback, not the first stop for every redirect.
So if I had to summarize the strategy in one sentence:
serve as many redirects as possible from cache, and only use the database when absolutely necessary.
⚖️ Tradeoffs
- Redis replication is async → possible gaps
- eventual consistency between cache + DB
- cache invalidation complexity
But:
- much faster reads
- scalable system
This is one of those designs where I’m very intentionally accepting some complexity in caching in exchange for much better read performance.
🧠 What I Learned
- Read-heavy systems = optimize caching first
- ID generation is a real problem at scale
- Simple systems get complicated when you add:
- scale
- availability
- latency constraints
📌 Final Thoughts
This problem looks simple on the surface, but it pulls in a lot of real-world distributed systems ideas:
- caching layers
- ID generation
- distributed systems tradeoffs
I’m still learning, but this one helped me understand how much of system design is really about identifying the hot path and optimizing around it.
🚀 Future Improvements
- analytics (click tracking)
- rate limiting per user
- custom domain support
- sharding DB by hash
- bloom filters to reduce DB hits